Chapter 1: DBMS
DATABASE MANAGEMENT SYSTEM
1.1 Introduction to Data, Database, Database System, and DBMS
Data refers to raw facts and figures without context, which can be processed to generate meaningful information.Database is a structured collection of data that is stored and accessed electronically. It allows for efficient data management and retrieval.Database System combines the database and the Database Management System (DBMS), which is software used to manage and manipulate the database.DBMS (Database Management System) is a software tool that facilitates the creation, retrieval, updating, and management of data in a database. It ensures data integrity, security, and consistency while providing a user-friendly interface for interacting with the data.1.2 Field, Record, Objects, Primary Key, Alternate Key, Candidate Key
- Field: A field is a single piece of data; it represents a column in a database table. For example, "First Name" in a student database.
- Record: A record is a collection of related fields that represent a single entity. For instance, a record for a student might include fields for "First Name," "Last Name," "Age," and "Grade."
- Objects: In the context of databases, objects can refer to any defined entity within the database, such as tables, views, indexes, etc.
- Primary Key: A primary key is a unique identifier for a record in a table. It ensures that no two records can have the same value for this field, such as a student ID.
- Alternate Key: An alternate key is any candidate key that is not chosen as the primary key. It can also uniquely identify a record, such as an email address.
- Candidate Key: A candidate key is a field or combination of fields that can uniquely identify a record in a table. There can be multiple candidate keys in a table.
1.3 Advantages of Using DBMS
- Data Independence: Applications are insulated from changes in data representation and storage.
- Efficient Data Access: DBMS uses sophisticated algorithms for data storage and retrieval.
- Data Integrity and Security: Enforces constraints to maintain data accuracy and restricts unauthorized access.
- Data Administration: Centralizes data management, improving consistency and reducing redundancy.
- Backup and Recovery: Provides mechanisms for data backup and recovery in case of failures.
- Concurrent Access: Allows multiple users to access the database simultaneously without conflicts.
Differences between DBMS and Flat file system :
| Feature | Flat File System | Database Management System (DBMS) |
|---|---|---|
| Data Structure | Data is stored in a single table or file, often in plain text. | Data is organized into tables with rows and columns. |
| Relationships | No relationships between data entries; data is independent. | Supports relationships between tables through keys (e.g., foreign keys). |
| Data Redundancy | High redundancy; the same data may be repeated across files. | Low redundancy; data is centralized and normalized. |
| Data Integrity | Low integrity; lacks mechanisms to enforce data accuracy. | High integrity; constraints can be applied to ensure data consistency. |
| Query Capability | Limited querying capabilities; often requires reading entire files. | Advanced querying capabilities using SQL for efficient data retrieval. |
| Scalability | Limited scalability; becomes cumbersome with large data sets. | Highly scalable; can handle large volumes of data efficiently. |
| Security | Basic security; less control over access and permissions. | Robust security features, including user authentication and access control. |
| Backup and Recovery | Manual backup processes; recovery can be difficult. | Automated backup and recovery options are available. |
| Concurrency | Limited or no support for multiple users accessing data simultaneously. | Supports multiple users accessing and modifying data concurrently. |
Differences between Database and DBMS.
| Feature | Database | DBMS |
|---|---|---|
| Definition | A collection of organized data that can be easily accessed, updated, and managed. | Software used to create, manage, and maintain a database. |
| Data Structure | Data is stored in tables, files, or other formats. | Provides a structured way to store and manage data. |
| Data Manipulation | Users directly interact with the data stored in the database. | Provides an interface for users to interact with the database. |
| Security | Relies on the DBMS for security features. | Enforces security measures like user authentication and access control. |
| Backup and Recovery | Depends on the DBMS for backup and recovery mechanisms. | Provides tools for backing up data and recovering from failures. |
| Concurrency Control | Relies on the DBMS to handle concurrent access to data. | Manages concurrent access to data and ensures data consistency. |
| Examples | A collection of customer records, financial transactions, or inventory data. | MySQL, Oracle, PostgreSQL, SQL Server. |
DDL and DML (Data Manipulation Language)
- DDL (Data Definition Language): A subset of SQL used to define and manage all database objects. Common DDL commands include
CREATE,ALTER, andDROP. - DML (Data Manipulation Language): A subset of SQL used for managing data within the database. Common DML commands include
SELECT,INSERT,UPDATE, andDELETE. 1.5 Database Models: Network Model, Hierarchical Model, Relational Database Model
This section provides a detailed explanation of three major database models: the Network Model, Hierarchical Model, and Relational Database Model, including diagrams, advantages, and disadvantages for each.Network Model
Explanation:
The Network Model organizes data in a graph structure, allowing multiple relationships between entities. This model supports complex relationships, including one-to-one, one-to-many, and many-to-many associations. Each record can have multiple parent and child records, making it flexible for representing interconnected data.Diagram:- Advantages:
- Flexibility: Supports complex relationships and multiple paths to the same record, enhancing data retrieval.
- Data Integrity: Relationships are maintained through owner-member pairs, ensuring data consistency.
- Efficient Access: Faster data retrieval due to multiple access paths.
- Complex Relationships: Better representation of many-to-many relationships compared to hierarchical models.
- Complexity: The structure can become complicated, making management and updates challenging.
- Navigation Difficulty: Requires a deep understanding of pointers for data navigation.
- Lack of Standardization: No universally accepted query language, leading to potential compatibility issues.
- Operational Anomalies: Changes in structure may require significant updates to application programs.
Hierarchical Model
Explanation:
The Hierarchical Model organizes data in a tree-like structure, where each record has a single parent and can have multiple children. This model is simple and intuitive but can be inflexible due to its rigid structure.Diagram:
Hierarchical Model Diagram
Advantages:- Simplicity: Easy to understand and implement due to its straightforward structure.
- Data Integrity: Enforces a clear parent-child relationship, reducing data redundancy.
- Fast Access: Efficient for queries that follow the hierarchical path.
- Lack of Flexibility: Difficult to reorganize or add new data relationships without significant restructuring.
- Redundancy Issues: Can lead to data redundancy if the same data is stored in multiple branches.
- Limited Relationships: Only supports one-to-many relationships, making it unsuitable for complex data scenarios.
- Difficult Maintenance: Changes in the hierarchy require updates to all affected records.
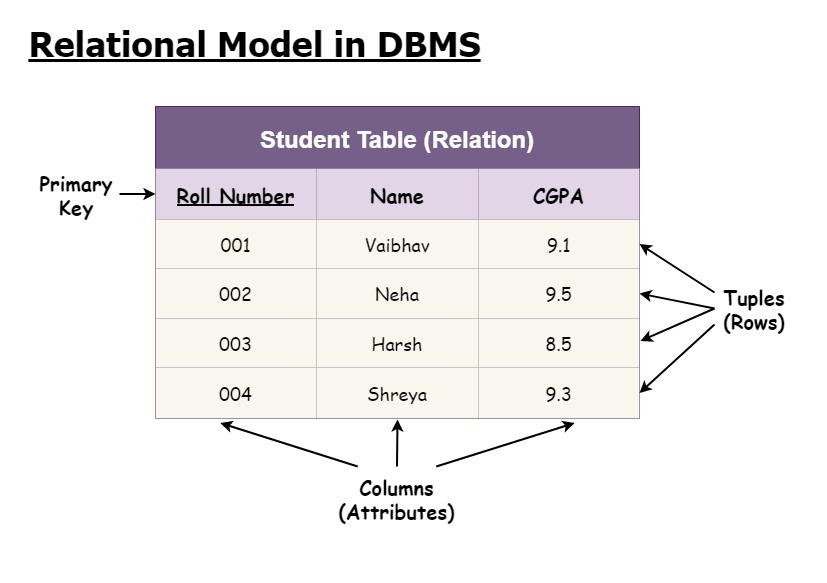
Relational Database Model
Explanation:
The Relational Database Model organizes data into tables (relations) that can be linked through foreign keys. This model is based on mathematical set theory and allows for a declarative query language (SQL) for data manipulation.Diagram:
Relational Model Diagram
Advantages:- Data Independence: Changes in the database structure do not affect application programs.
- Flexibility: Supports complex queries and relationships through SQL.
- Normalization: Reduces data redundancy through normalization techniques.
- Standardization: SQL provides a standardized way to interact with the database.
- Performance Overhead: Complex queries can lead to slower performance compared to other models.
- Complexity in Design: Designing a relational database requires careful planning and normalization.
- Scalability Issues: May face challenges when scaling to very large datasets or high transaction volumes.
- Dependency on SQL: Requires knowledge of SQL for effective data manipulation and retrieval.
- Database Security.
- Database security refers to the measures and practices implemented to protect databases from unauthorized access, misuse, and threats. It encompasses a variety of controls, tools, and procedures designed to safeguard the confidentiality, integrity, and availability of data stored within a database. As data breaches and cyber threats become increasingly sophisticated, robust database security is essential for organizations to protect sensitive information and maintain trust with customers.
Importance of Database Security
- Protects Sensitive Information: Database security measures prevent unauthorized access to personal, financial, and proprietary data, safeguarding it from malicious actors.
- Ensures Compliance: Organizations must adhere to regulatory requirements such as GDPR, HIPAA, and PCI DSS. Effective database security helps ensure compliance with these regulations, avoiding potential fines and legal issues.
- Maintains Trust: By ensuring the integrity and availability of data, organizations can maintain customer trust and confidence in their services.
- Prevents Data Breaches: Strong database security reduces the risk of costly and damaging security incidents that can lead to data loss or theft.
Common Causes of Database Security Breaches
- Weak Authentication: The use of default, weak, or compromised credentials can allow attackers to gain unauthorized access. Many breaches occur due to weak passwords or failure to change default passwords.
- Inadequate Access Controls: Over-permissioned accounts and poorly defined role-based access controls increase the risk of accidental or malicious actions.
- Unpatched Vulnerabilities: Failure to apply timely software updates can leave databases exposed to known vulnerabilities that attackers can exploit.
- SQL Injection Attacks: Attackers can manipulate input fields in web applications to execute arbitrary SQL code, leading to unauthorized access or data manipulation.
- Insufficient Encryption: Data that is not encrypted is vulnerable to interception and unauthorized access, especially during transmission or when stored on compromised systems.
- Misconfiguration: Poorly configured database settings, such as open database ports or excessive permissions, can expose databases to attacks.
- Insider Threats: Malicious or negligent actions by employees or partners can lead to data breaches, whether intentional or accidental.
- Human Error: Mistakes such as sharing passwords or failing to follow security protocols can significantly increase the risk of a data breach.
- Malware: Software designed to exploit vulnerabilities can be introduced into the database environment through various means, including infected devices.
- Denial-of-Service Attacks: Attackers can overwhelm database servers with excessive requests, rendering them unavailable to legitimate users.
Strategies for Hardening Database Security
- Implement Access Controls: Use role-based access control (RBAC) to ensure that users have the minimum necessary permissions to perform their job functions.
- Use Strong Authentication: Employ multi-factor authentication (MFA) and enforce strong password policies to enhance security.
- Encrypt Data: Encrypt sensitive data both in transit and at rest to protect it from unauthorized access.
- Regularly Update Software: Apply security patches and updates promptly to address known vulnerabilities.
- Conduct Security Audits: Regularly review and audit database security policies and practices to identify and address potential weaknesses.
- Monitor Database Activity: Implement real-time monitoring and logging to detect suspicious activity and respond to potential threats quickly.
- Educate Employees: Provide training on data security best practices to reduce the risk of human error and insider threats.
- Develop an Incident Response Plan: Prepare a clear plan for responding to security incidents to minimize damage and recover quickly.
- Utilize Firewalls and Intrusion Detection Systems: Protect databases from unauthorized access and malicious attacks with network security measures.
- Backup Data Regularly: Ensure that data is backed up securely and can be restored in case of data loss or corruption.
1.6 Concept of Normalization: 1NF, 2NF, 3NF
Normalization is a systematic approach to organizing data in a database to minimize redundancy and improve data integrity. It involves dividing a database into tables and defining relationships between them. The process is typically broken down into several normal forms, with the first three being the most commonly used: First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF).First Normal Form (1NF)
Definition:
A table is in First Normal Form (1NF) if:- All entries in a column are atomic (indivisible).
- Each column contains only one value per row.
- Each row is unique, which requires a primary key.
Consider a table of students with courses:This table is not in 1NF because the "Courses" column contains multiple values (e.g., "Math, Science").To convert to 1NF, we separate the courses into individual rows:Student_ID Name Courses 1 Alice Math, Science 2 Bob History 3 Carol Math, History Now, each cell contains atomic values, and the table meets the criteria for 1NF.Student_ID Name Course 1 Alice Math 1 Alice Science 2 Bob History 3 Carol Math 3 Carol History Second Normal Form (2NF)
Definition:
A table is in Second Normal Form (2NF) if:- It is already in 1NF.
- All non-key attributes are fully functionally dependent on the primary key (no partial dependency).
Using the previous example, assume we have the following table:This table is in 1NF, but it is not in 2NF because the "Instructor_Age" is only dependent on "Instructor" and not on the entire primary key ("Student_ID", "Course").To convert to 2NF, we create two tables:Student_ID Course Instructor Instructor_Age 1 Math Dr. Smith 45 1 Science Dr. Jones 50 2 History Dr. Brown 40 3 Math Dr. Smith 45 3 History Dr. Brown 40 - Student_Course Table:
Student_ID Course Instructor 1 Math Dr. Smith 1 Science Dr. Jones 2 History Dr. Brown 3 Math Dr. Smith 3 History Dr. Brown - Instructor Table:
Now, all non-key attributes in the "Student_Course" table are fully dependent on the primary key, satisfying 2NF.Instructor Instructor_Age Dr. Smith 45 Dr. Jones 50 Dr. Brown 40 Third Normal Form (3NF)
Definition:
A table is in Third Normal Form (3NF) if:- It is already in 2NF.
- There are no transitive dependencies (non-key attributes should not depend on other non-key attributes).
Continuing from the previous example, consider the "Student_Course" table:This table is in 2NF, but it is not in 3NF because "Instructor_Age" is dependent on "Instructor," which is a non-key attribute.To convert to 3NF, we can keep the "Instructor" and "Instructor_Age" in the separate "Instructor" table created earlier. The "Student_Course" table would then look like this:Student_ID Course Instructor Instructor_Age 1 Math Dr. Smith 45 1 Science Dr. Jones 50 2 History Dr. Brown 40 3 Math Dr. Smith 45 3 History Dr. Brown 40 The "Instructor" table remains the same:Student_ID Course Instructor 1 Math Dr. Smith 1 Science Dr. Jones 2 History Dr. Brown 3 Math Dr. Smith 3 History Dr. Brown Now, the "Student_Course" table is in 3NF because all non-key attributes are directly dependent only on the primary key.Instructor Instructor_Age Dr. Smith 45 Dr. Jones 50 Dr. Brown 40 Summary of Normal Forms
- 1NF: Ensures atomicity and uniqueness of rows.
- 2NF: Eliminates partial dependencies on a composite primary key.
- 3NF: Eliminates transitive dependencies among non-key attributes.
- 1.7 Centralized Vs. Distributed Database
Feature Centralized Database Distributed Database Definition A single database located at one central location. Multiple databases spread across different physical locations. Data Access Accessed from a single location, leading to potential bottlenecks. Accessed from multiple locations, improving speed and efficiency. Management Easier to manage, update, and back up due to a single location. More complex management due to multiple locations and synchronization needs. Data Consistency Generally offers higher consistency as all data is in one place. May face challenges with consistency due to data replication across locations. Failure Impact If the central database fails, all users lose access. If one database fails, others remain accessible, enhancing reliability. Cost Typically less expensive to set up and maintain. More costly due to the need for multiple systems and complex infrastructure. Scalability Scaling can be difficult as it involves upgrading a single system. Easier to scale by adding more databases or nodes in different locations. Performance Performance can degrade with high user load due to a single point of access. Generally better performance as data can be retrieved from the nearest location. Security Easier to secure since data is stored in one location. More challenging to secure due to multiple access points and locations. Data Redundancy Minimal data redundancy as all data is centralized. Higher chances of data redundancy due to data being stored in multiple locations.



Comments
Post a Comment